Publications
publications by categories in reversed chronological order.
* = equal contribution.
2026
-
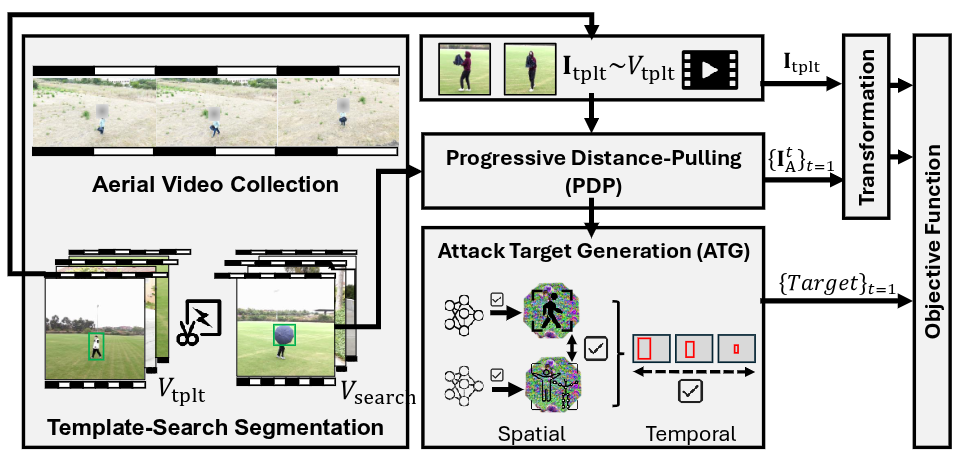 FlyTrap: Physical Distance-Pulling Attack Towards Camera-based Autonomous Target Tracking SystemsShaoyuan Xie, Mohamad Fakih, Junchi Lu, Fayzah Alshammari, Ningfei Wang, Takami Sato, Halima Bouzidi, Mohammad Abdullah Al Faruque, and Qi Alfred ChenNetwork and Distributed System Security Symposium (NDSS), 2026
FlyTrap: Physical Distance-Pulling Attack Towards Camera-based Autonomous Target Tracking SystemsShaoyuan Xie, Mohamad Fakih, Junchi Lu, Fayzah Alshammari, Ningfei Wang, Takami Sato, Halima Bouzidi, Mohammad Abdullah Al Faruque, and Qi Alfred ChenNetwork and Distributed System Security Symposium (NDSS), 2026Autonomous Target Tracking (ATT) systems, especially ATT drones, are widely used in applications such as surveillance, border control, and law enforcement. Thus, the security of ATT is highly critical for real-world applications. Under the scope, we present a new type of attack: distance-pulling attacks (DPA), which exploits vulnerabilities in ATT systems to dangerously reduce tracking distances, leading to drone capturing, increased susceptibility to sensor attacks, or even physical collisions. We present FlyTrap, a novel physicalworld attack framework that employs an adversarial umbrella as a deployable and domain-specific attack vector to achieve these goals. This demonstration will include videos and figures of the generated FlyTrap adversarial umbrellas and the end-to-end consequences.

2025
-
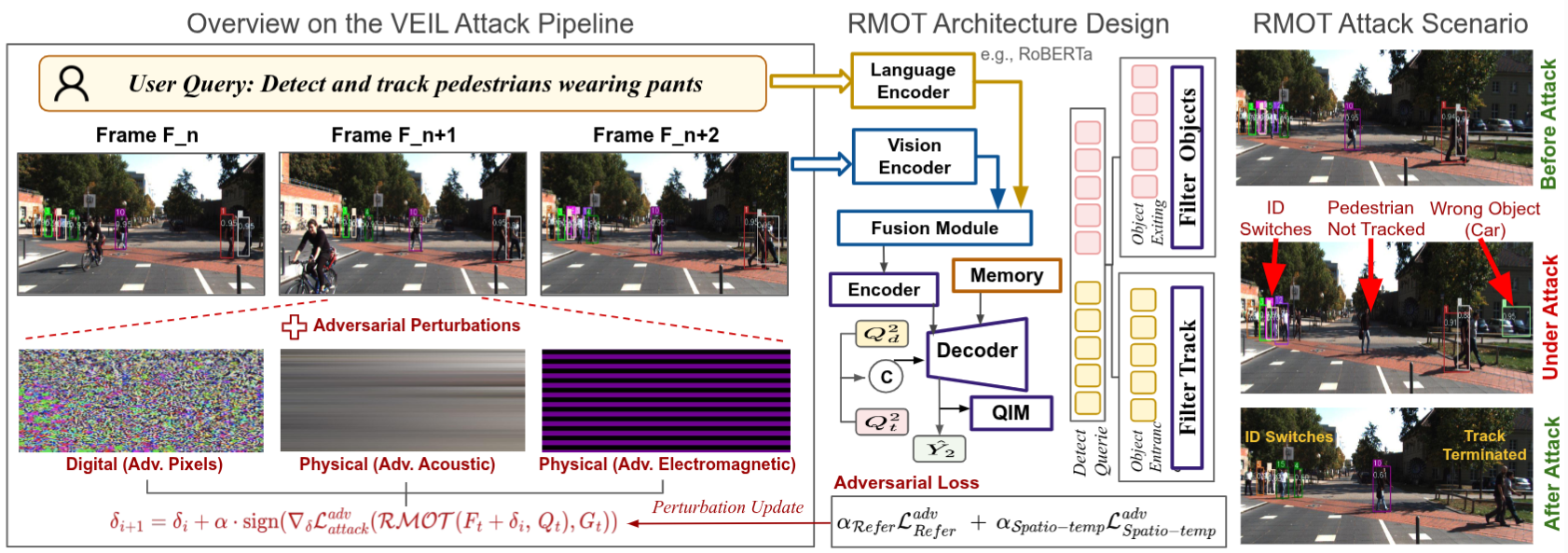 See No Evil: Adversarial Attacks Against Linguistic-Visual Association in Referring Multi-Object Tracking SystemsHalima Bouzidi, Haoyu Liu, and Mohammad Abdullah Al FaruqueNeurIPS 2025 Workshop: Reliable ML from Unreliable Data, 2025
See No Evil: Adversarial Attacks Against Linguistic-Visual Association in Referring Multi-Object Tracking SystemsHalima Bouzidi, Haoyu Liu, and Mohammad Abdullah Al FaruqueNeurIPS 2025 Workshop: Reliable ML from Unreliable Data, 2025Language-vision understanding has driven the development of advanced perception systems, most notably the emerging paradigm of Referring Multi-Object Tracking (RMOT). By leveraging natural-language queries, RMOT systems can selectively track objects that satisfy a given semantic description, guided through Transformer-based spatial-temporal reasoning modules. End-to-End (E2E) RMOT models further unify feature extraction, temporal memory, and spatial reasoning within a Transformer backbone, enabling long-range spatial-temporal modeling over fused textual-visual representations. Despite these advances, the reliability and robustness of RMOT remain underexplored. In this paper, we examine the security implications of RMOT systems from a design-logic perspective, identifying adversarial vulnerabilities that compromise both the linguistic-visual referring and track-object matching components. Additionally, we uncover a novel vulnerability in advanced RMOT models employing FIFO-based memory, whereby targeted and consistent attacks on their spatial-temporal reasoning introduce errors that persist within the history buffer over multiple subsequent frames. We present VEIL, a novel adversarial framework designed to disrupt the unified referring-matching mechanisms of RMOT models. We show that carefully crafted digital and physical perturbations can corrupt the tracking logic reliability, inducing track ID switches and terminations. We conduct comprehensive evaluations using the Refer-KITTI dataset to validate the effectiveness of VEIL and demonstrate the urgent need for security-aware RMOT designs for critical large-scale applications.
-
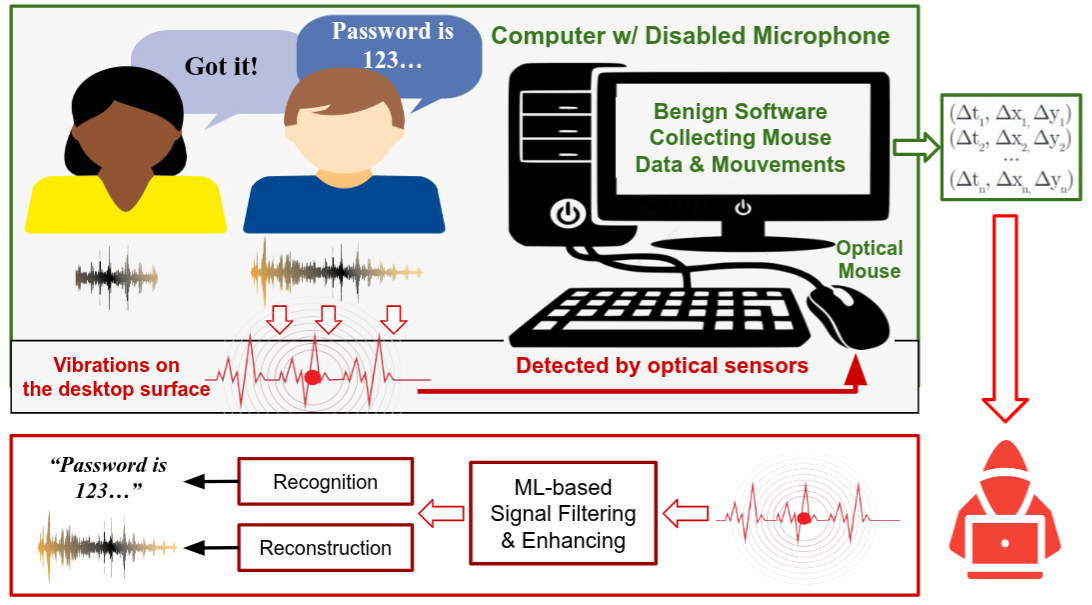 Invisible Ears at Your Fingertips: Acoustic Eavesdropping via Mouse SensorsMohamad Habib Fakih, Rahul Dharmaji, Youssef Mahmoud, Halima Bouzidi, and Mohammad Abdullah Al FaruqueAnnual Computer Security Applications Conference (ACSAC), 2025
Invisible Ears at Your Fingertips: Acoustic Eavesdropping via Mouse SensorsMohamad Habib Fakih, Rahul Dharmaji, Youssef Mahmoud, Halima Bouzidi, and Mohammad Abdullah Al FaruqueAnnual Computer Security Applications Conference (ACSAC), 2025Modern optical mouse sensors, with their advanced precision and high responsiveness, possess an often overlooked vulnerability: they can be exploited for side-channel attacks. This paper introduces Mic-E-Mouse, the first-ever side-channel attack that targets high-performance optical mouse sensors to covertly eavesdrop on users. We demonstrate that audio signals can induce subtle surface vibrations detectable by a mouse’s optical sensor. Remarkably, user-space software on popular operating systems can collect and broadcast this sensitive side channel, granting attackers access to raw mouse data without requiring direct system-level permissions. Initially, the vibration signals extracted from mouse data are of poor quality due to non-uniform sampling, a non-linear frequency response, and significant quantization. To overcome these limitations, Mic-E-Mouse employs a sophisticated end-to-end data filtering pipeline that combines Wiener filtering, resampling corrections, and an innovative encoder-only spectrogram neural filtering technique. We evaluate the attack’s efficacy across diverse conditions, including speaking volume, mouse polling rate and DPI, surface materials, speaker languages, and environmental noise. In controlled environments, Mic-E-Mouse improves the signal-to-noise ratio (SNR) by up to +19 dB for speech reconstruction. Furthermore, our results demonstrate a speech recognition accuracy of roughly 42% to 61% on the AudioMNIST and VCTK datasets.
-
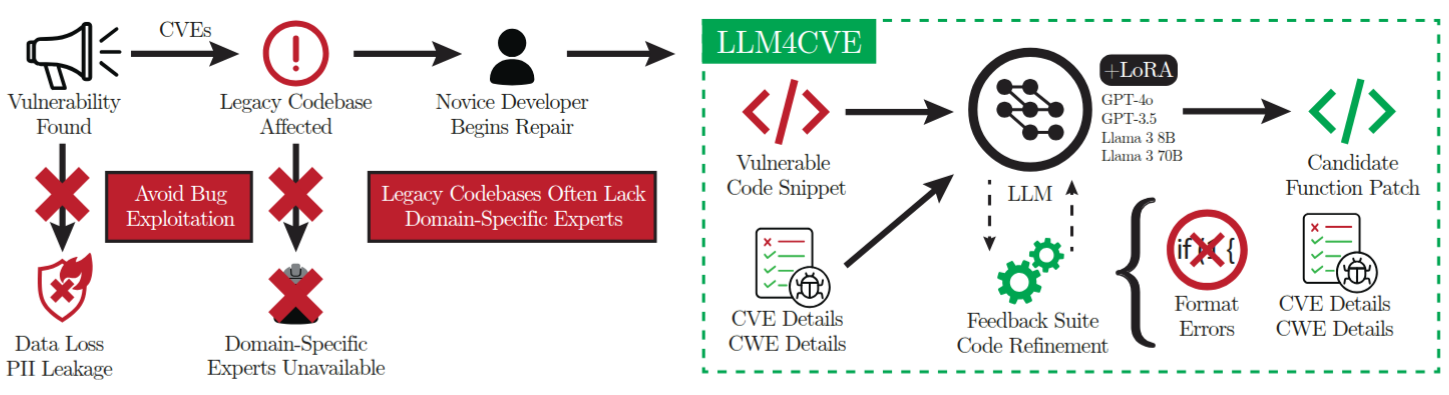 LLM4CVE: Enabling Iterative Automated Vulnerability Repair with Large Language ModelsMohamad Fakih, Rahul Dharmaji, Halima Bouzidi, Gustavo Quiros Araya, Oluwatosin Ogundare, and Mohammad Abdullah Al FaruqueIEEE Euromicro Conference on Digital System Design (DSD), 2025
LLM4CVE: Enabling Iterative Automated Vulnerability Repair with Large Language ModelsMohamad Fakih, Rahul Dharmaji, Halima Bouzidi, Gustavo Quiros Araya, Oluwatosin Ogundare, and Mohammad Abdullah Al FaruqueIEEE Euromicro Conference on Digital System Design (DSD), 2025Software vulnerabilities continue to be ubiquitous, even in the era of AI-powered code assistants, advanced static analysis tools, and the adoption of extensive testing frameworks. It has become apparent that we must not simply prevent these bugs, but also eliminate them in a quick, efficient manner. Yet, human code intervention is slow, costly, and can often lead to further security vulnerabilities, especially in legacy codebases. The advent of highly advanced Large Language Models (LLM) has opened up the possibility for many software defects to be patched automatically. We propose LLM4CVE an LLM-based iterative pipeline that robustly fixes vulnerable functions in real-world code with high accuracy. We examine our pipeline with State-of-the-Art LLMs, such as GPT-3.5, GPT-4o, Llama 38B, and Llama 3 70B. We achieve a human-verified quality score of 8.51/10 and an increase in groundtruth code similarity of 20% with Llama 3 70B. To promote further research in the area of LLM-based vulnerability repair, we publish our testing apparatus, fine-tuned weights, and experimental data on our website
-
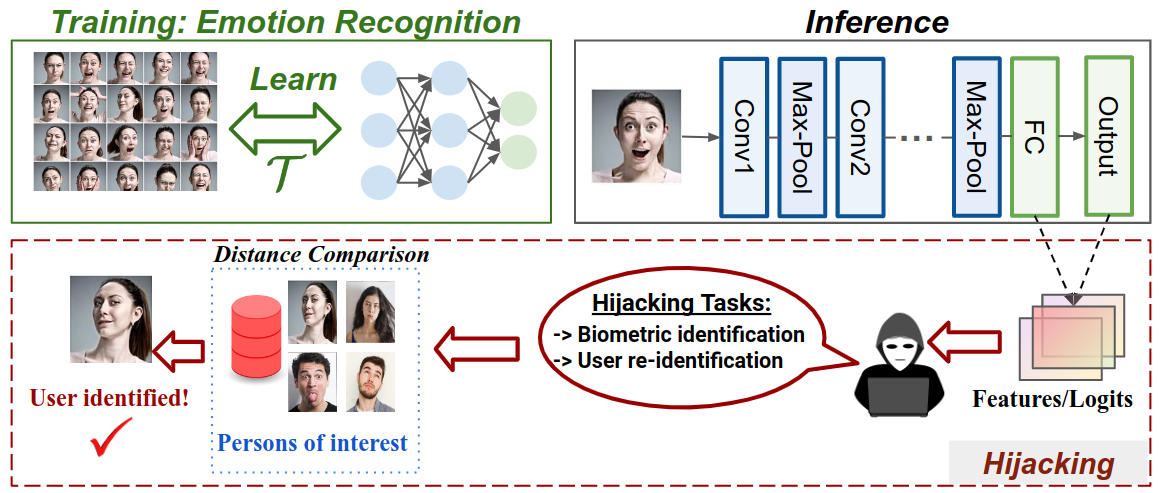 SnatchML: Hijacking ML Models without Training AccessMahmoud Ghorbel, Halima Bouzidi, Ioan Marius Bilasco, and Ihsen AlouaniIEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2025
SnatchML: Hijacking ML Models without Training AccessMahmoud Ghorbel, Halima Bouzidi, Ioan Marius Bilasco, and Ihsen AlouaniIEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2025The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.




2024
-
 An Evaluation Bench for the Exploration of Machine Learning Deployment Solutions on Embedded PlatformsEric Jenn, Floris Thiant, Theo Allouche, Halima Bouzidi, Ramon Conejo-Laguna, Omar Hlimi, Cyril Louis-Stanislas, Christophe Marabotto, Smail Niar, Serge Romaric Tembo Mouafo, and Philippe ThierionIn European Congress Embedded Real Time Systems (ERTS), Jun 2024
An Evaluation Bench for the Exploration of Machine Learning Deployment Solutions on Embedded PlatformsEric Jenn, Floris Thiant, Theo Allouche, Halima Bouzidi, Ramon Conejo-Laguna, Omar Hlimi, Cyril Louis-Stanislas, Christophe Marabotto, Smail Niar, Serge Romaric Tembo Mouafo, and Philippe ThierionIn European Congress Embedded Real Time Systems (ERTS), Jun 2024 -
 Efficient Deployment of Deep Neural Networks on Hardware Devices for Edge AIHalima BouzidiPhD Thesis, Université Polytechnique Hauts-de-France, Jan 2024
Efficient Deployment of Deep Neural Networks on Hardware Devices for Edge AIHalima BouzidiPhD Thesis, Université Polytechnique Hauts-de-France, Jan 2024Neural Networks (NN) have become a leading force in today’s digital landscape. Inspired by the human brain, their intricate design allows them to recognize patterns, make informed decisions, and even predict forthcoming scenarios with impressive accuracy. NN are widely deployed in Internet of Things (IoT) systems, further elevating interconnected devices’ capabilities by empowering them to learn and auto-adapt in real-time contexts. However, the proliferation of data produced by IoT sensors makes it difficult to send them to a centralized cloud for processing. This is where the allure of edge computing becomes captivating. Processing data closer to where it originates -at the edge- reduces latency, makes real-time decisions with less effort, and efficiently manages network congestion.Integrating NN on edge devices for IoT systems enables more efficient and responsive solutions, ushering in a new age of self-sustaining Edge AI. However, Deploying NN on resource-constrained edge devices presents a myriad of challenges: (i) The inherent complexity of neural network architectures, which requires significant computational and memory capabilities. (ii) The limited power budget of IoT devices makes the NN inference prone to rapid energy depletion, drastically reducing system utility. (iii) The hurdle of ensuring harmony between NN and HW designs as they evolve at different rates. (iv) The lack of adaptability to the dynamic runtime environment and the intricacies of input data.Addressing these challenges, this thesis aims to establish innovative methods that extend conventional NN design frameworks, notably Neural Architecture Search (NAS). By integrating HW and runtime contextual features, our methods aspire to enhance NN performances while abstracting the need for the human-in-loop. Firstly, we incorporate HW properties into the NAS by tailoring the design of NN to clock frequency variations (DVFS) to minimize energy footprint. Secondly, we leverage dynamicity within NN from a design perspective, culminating in a comprehensive Hardware-aware Dynamic NAS with DVFS features. Thirdly, we explore the potential of Graph Neural Networks (GNN) at the edge by developing a novel HW-aware NAS with distributed computing features on heterogeneous MPSoC. Fourthly, we address the SW/HW co-optimization on heterogeneous MPSoCs by proposing an innovative scheduling strategy that leverages NN adaptability and parallelism across computing units. Fifthly, we explore the prospect of ML4ML – Machine Learning for Machine Learning by introducing techniques to estimate NN performances on edge devices using neural architectural features and ML-based predictors. Finally, we develop an end-to-end self-adaptive evolutionary HW-aware NAS framework that progressively learns the importance of NN parameters to guide the search process toward Pareto optimality effectively.Our methods can contribute to elaborating an end-to-end design framework for neural networks on edge hardware devices. They enable leveraging multiple optimization opportunities at both the software and hardware levels, thus improving the performance and efficiency of Edge AI.
-
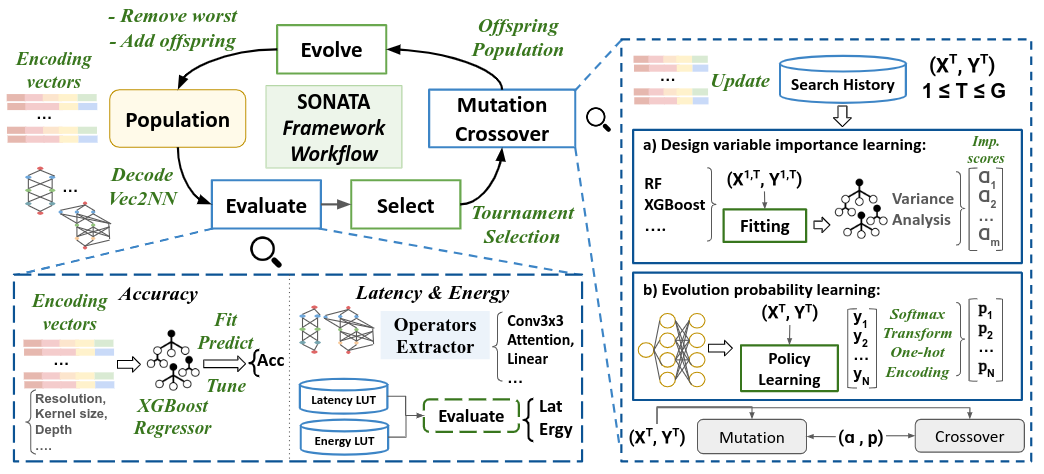 SONATA: Self-adaptive Evolutionary Framework for Hardware-aware Neural Architecture SearchHalima Bouzidi, Smaïl Niar, Hamza Ouarnoughi, and El-Ghazali TalbiArXiv, Jan 2024
SONATA: Self-adaptive Evolutionary Framework for Hardware-aware Neural Architecture SearchHalima Bouzidi, Smaïl Niar, Hamza Ouarnoughi, and El-Ghazali TalbiArXiv, Jan 2024Recent advancements in Artificial Intelligence (AI), driven by Neural Networks (NN), demand innovative neural architecture designs, particularly within the constrained environments of Internet of Things (IoT) systems, to balance performance and efficiency. HW-aware Neural Architecture Search (HW-aware NAS) emerges as an attractive strategy to automate the design of NN using multi-objective optimization approaches, such as evolutionary algorithms. However, the intricate relationship between NN design parameters and HW-aware NAS optimization objectives remains an underexplored research area, overlooking opportunities to effectively leverage this knowledge to guide the search process accordingly. Furthermore, the large amount of evaluation data produced during the search holds untapped potential for refining the optimization strategy and improving the approximation of the Pareto front. Addressing these issues, we propose SONATA, a self-adaptive evolutionary algorithm for HW-aware NAS. Our method leverages adaptive evolutionary operators guided by the learned importance of NN design parameters. Specifically, through tree-based surrogate models and a Reinforcement Learning agent, we aspire to gather knowledge on ’How’ and ’When’ to evolve NN architectures. Comprehensive evaluations across various NAS search spaces and hardware devices on the ImageNet-1k dataset have shown the merit of SONATA with up to 0.25% improvement in accuracy and up to 2.42x gains in latency and energy. Our SONATA has seen up to sim$93.6% Pareto dominance over the native NSGA-II, further stipulating the importance of self-adaptive evolution operators in HW-aware NAS.
-
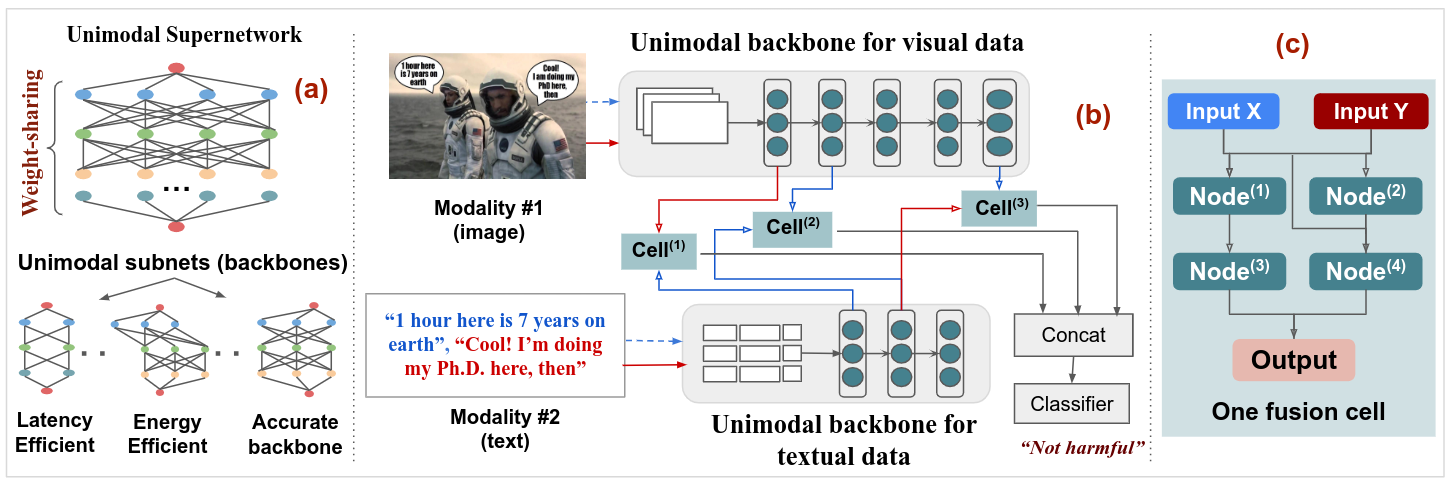 Harmonic-NAS: Hardware-Aware Multimodal Neural Architecture Search on Resource-constrained DevicesMohamed Imed Eddine Ghebriout, Halima Bouzidi, Smail Niar, and Hamza OuarnoughiIn , 11–14 nov 2024
Harmonic-NAS: Hardware-Aware Multimodal Neural Architecture Search on Resource-constrained DevicesMohamed Imed Eddine Ghebriout, Halima Bouzidi, Smail Niar, and Hamza OuarnoughiIn , 11–14 nov 2024The recent surge of interest surrounding Multimodal Neural Networks (MM-NN) is attributed to their ability to effectively process and integrate multiscale information from diverse data sources. MM-NNs extract and fuse features from multiple modalities using adequate unimodal backbones and specific fusion networks. Although this helps strengthen the multimodal information representation, designing such networks is labor-intensive. It requires tuning the architectural parameters of the unimodal backbones, choosing the fusing point, and selecting the operations for fusion. Furthermore, multimodality AI is emerging as a cutting-edge option in Internet of Things (IoT) systems where inference latency and energy consumption are critical metrics in addition to accuracy. In this paper, we propose Harmonic-NAS, a framework for the joint optimization of unimodal backbones and multimodal fusion networks with hardware awareness on resource-constrained devices. Harmonic-NAS involves a two-tier optimization approach for the unimodal backbone architectures and fusion strategy and operators. By incorporating the hardware dimension into the optimization, evaluation results on various devices and multimodal datasets have demonstrated the superiority of Harmonic-NAS over state-of-the-art approaches achieving up to 10.9% accuracy improvement, 1.91x latency reduction, and 2.14x energy efficiency gain.




2023
-
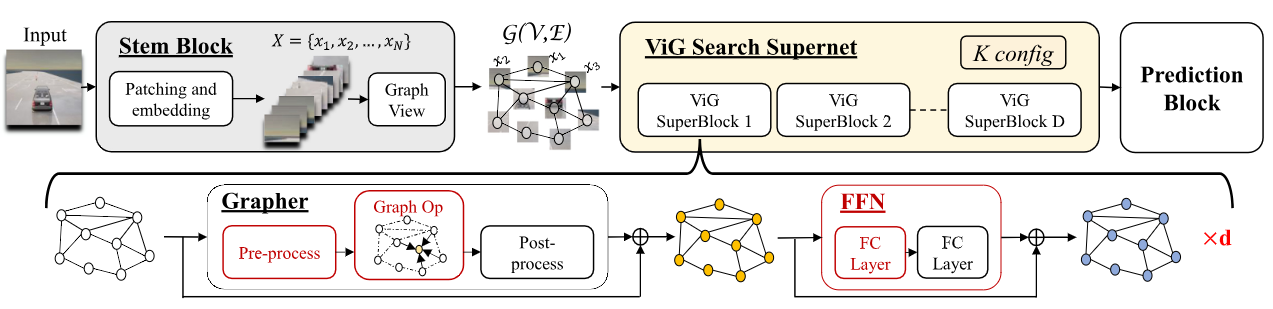 MaGNAS: A Mapping-Aware Graph Neural Architecture Search Framework for Heterogeneous MPSoC DeploymentMohanad Odema*, Halima Bouzidi*, Hamza Ouarnoughi, Smail Niar, and Mohammad Abdullah Al FaruqueACM Transactions on Embedded Computing Systems, Sep 2023
MaGNAS: A Mapping-Aware Graph Neural Architecture Search Framework for Heterogeneous MPSoC DeploymentMohanad Odema*, Halima Bouzidi*, Hamza Ouarnoughi, Smail Niar, and Mohammad Abdullah Al FaruqueACM Transactions on Embedded Computing Systems, Sep 2023Graph Neural Networks (GNNs) are becoming increasingly popular for vision-based applications due to their intrinsic capacity in modeling structural and contextual relations between various parts of an image frame. On another front, the rising popularity of deep vision-based applications at the edge has been facilitated by the recent advancements in heterogeneous multi-processor Systems on Chips (MPSoCs) that enable inference under real-time, stringent execution requirements. By extension, GNNs employed for vision-based applications must adhere to the same execution requirements. Yet contrary to typical deep neural networks, the irregular flow of graph learning operations poses a challenge to running GNNs on such heterogeneous MPSoC platforms. In this paper, we propose a novel unified design-mapping approach for efficient processing of vision GNN workloads on heterogeneous MPSoC platforms. Particularly, we develop MaGNAS, a mapping-aware Graph Neural Architecture Search framework. MaGNAS proposes a GNN architectural design space coupled with prospective mapping options on a heterogeneous SoC to identify model architectures that maximize on-device resource efficiency. To achieve this, MaGNAS employs a two-tier evolutionary search to identify optimal GNNs and mapping pairings that yield the best performance trade-offs. Through designing a supernet derived from the recent Vision GNN (ViG) architecture, we conducted experiments on four (04) state-of-the-art vision datasets using both (i) a real hardware SoC platform (NVIDIA Xavier AGX) and (ii) a performance/cost model simulator for DNN accelerators. Our experimental results demonstrate that MaGNAS is able to provide 1.57\texttimes latency speedup and is 3.38\texttimes more energy-efficient for several vision datasets executed on the Xavier MPSoC vs. the GPU-only deployment while sustaining an average 0.11% accuracy reduction from the baseline.
-
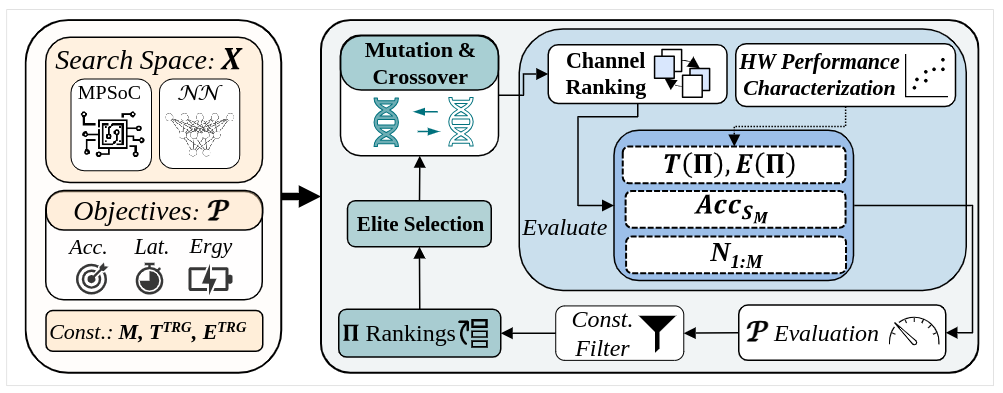 Map-and-Conquer: Energy-Efficient Mapping of Dynamic Neural Nets onto Heterogeneous MPSoCsHalima Bouzidi, Mohanad Odema, Hamza Ouarnoughi, Smail Niar, and Mohammad Abdullah Al FaruqueIn , Jul 2023
Map-and-Conquer: Energy-Efficient Mapping of Dynamic Neural Nets onto Heterogeneous MPSoCsHalima Bouzidi, Mohanad Odema, Hamza Ouarnoughi, Smail Niar, and Mohammad Abdullah Al FaruqueIn , Jul 2023HiPEAC Award
Heterogeneous MPSoCs comprise diverse processing units of varying compute capabilities. To date, the mapping strategies of neural networks (NNs) onto such systems are yet to exploit the full potential of processing parallelism, made possible through both the intrinsic NNs’ structure and underlying hardware composition. In this paper, we propose a novel framework to effectively map NNs onto heterogeneous MPSoCs in a manner that enables them to leverage the underlying processing concurrency. Specifically, our approach identifies an optimal partitioning scheme of the NN along its ‘width’ dimension, which facilitates deployment of concurrent NN blocks onto different hardware computing units. Additionally, our approach contributes a novel scheme to deploy partitioned NNs onto the MPSoC as dynamic multi-exit networks for additional performance gains. Our experiments on a standard MPSoC platform have yielded dynamic mapping configurations that are 2.1x more energy-efficient than the GPU-only mapping while incurring 1.7x less latency than DLA-only mapping.
-
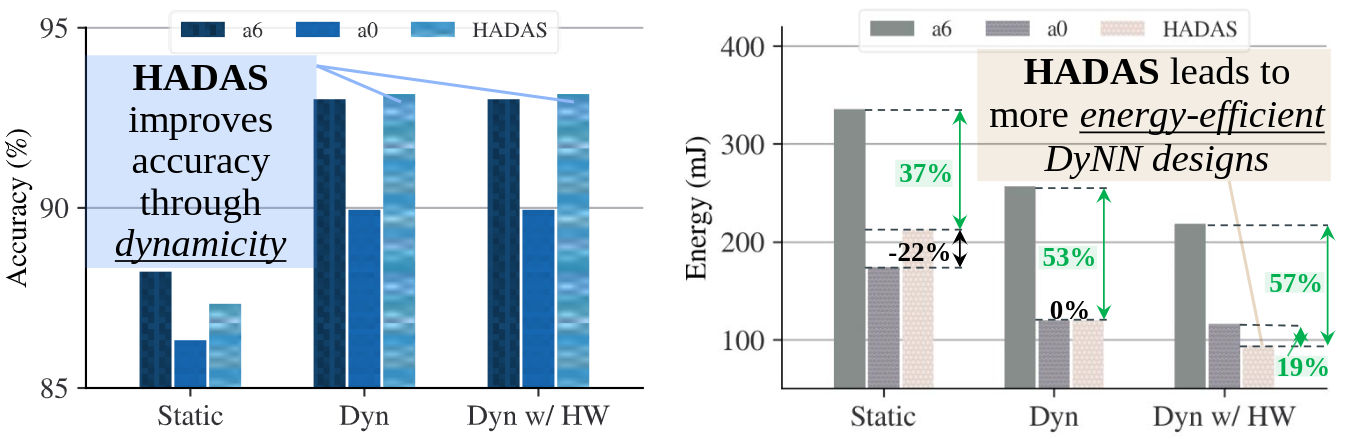 HADAS: Hardware-Aware Dynamic Neural Architecture Search for Edge Performance ScalingHalima Bouzidi, Mohanad Odema, Hamza Ouarnoughi, Mohammad Abdullah Al Faruque, and Smail NiarIn , Apr 2023
HADAS: Hardware-Aware Dynamic Neural Architecture Search for Edge Performance ScalingHalima Bouzidi, Mohanad Odema, Hamza Ouarnoughi, Mohammad Abdullah Al Faruque, and Smail NiarIn , Apr 2023Best Paper Award Nominee
Dynamic neural networks (DyNNs) have become viable techniques to enable intelligence on resource-constrained edge devices while maintaining computational efficiency. In many cases, the implementation of DyNNs can be sub-optimal due to its underlying backbone architecture being developed at the design stage independent of both: (i) potential support for dynamic computing, e.g. early exiting, and (ii) resource efficiency features of the underlying hardware, e.g., dynamic voltage and frequency scaling (DVFS). Addressing this, we present HADAS, a novel Hardware-Aware Dynamic Neural Architecture Search framework that realizes DyNN architectures whose backbone, early exiting features, and DVFS settings have been jointly optimized to maximize performance and resource efficiency. Our experiments using the CIFAR-100 dataset and a diverse set of edge computing platforms have shown that HADAS can elevate dynamic models’ energy efficiency by up to 57% for the same level of accuracy scores. Our code is available at https://github.com/HalimaBouzidi/HADAS



2022
-
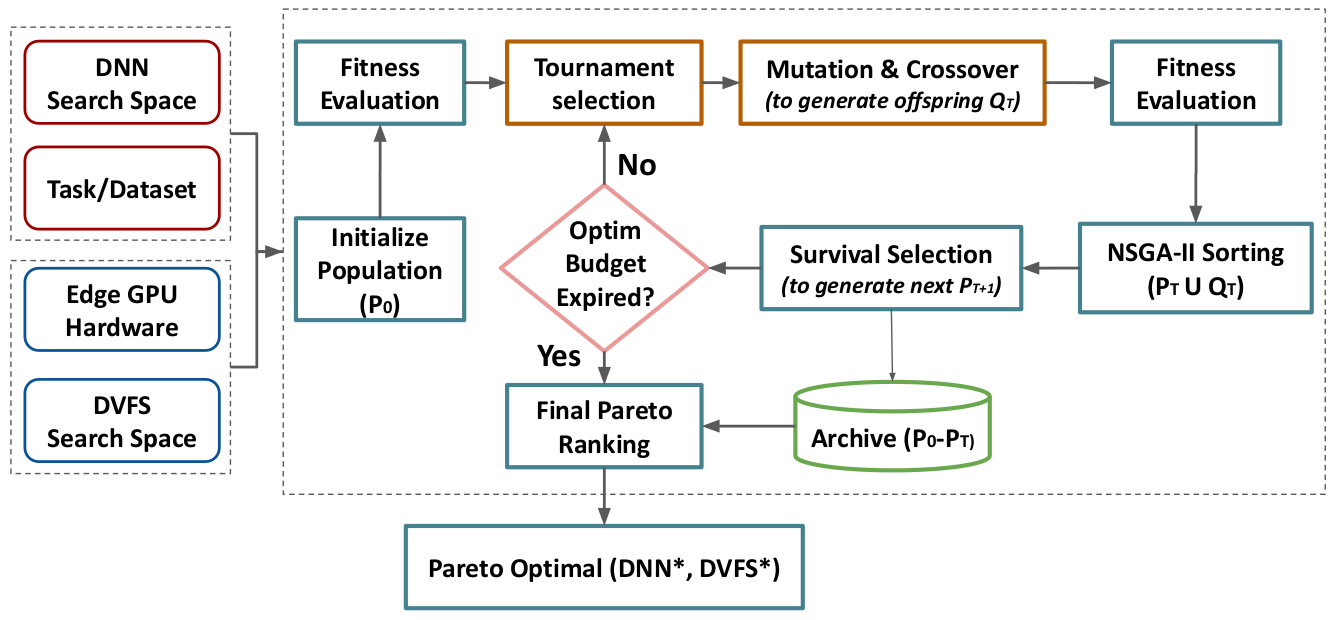 Co-Optimization of DNN and Hardware Configurations on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, Smail Niar, El-Ghazali Talbi, and Abdessamad Ait El CadiIn , Apr 2022
Co-Optimization of DNN and Hardware Configurations on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, Smail Niar, El-Ghazali Talbi, and Abdessamad Ait El CadiIn , Apr 2022The ever-increasing complexity of both Deep Neural Networks (DNN) and hardware accelerators has made the co-optimization of these domains extremely complex. Previous works typically focus on optimizing DNNs given a fixed hardware configuration or optimizing a specific hardware architecture given a fixed DNN model. Recently, the importance of the joint exploration of the two spaces drew more and more attention. Our work targets the co-optimization of DNN and hardware configurations on edge GPU accelerators. We propose an evolutionary-based co-optimization strategy by considering three metrics: DNN accuracy, execution latency, and power consumption. By combining the two search spaces, a larger number of configurations can be explored in a short time interval. In addition, a better tradeoff between DNN accuracy and hardware efficiency can be obtained. Experimental results show that the co-optimization outperforms the optimization of DNN for fixed hardware configuration with up to 53% hardware efficiency gains with the same accuracy and inference time.
-
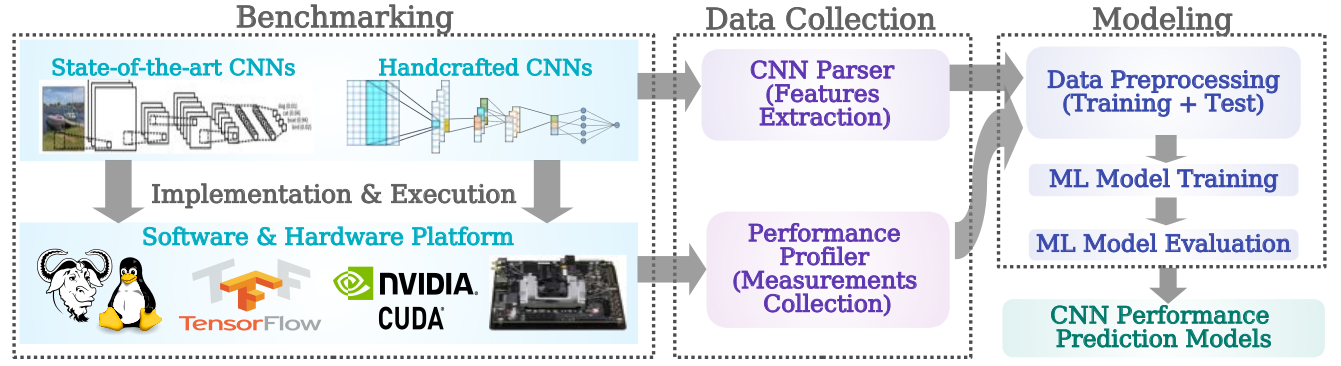 Performance Modeling of Computer Vision-based CNN on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, Smail Niar, and Abdessamad Ait El CadiACM Transactions on Embedded Computing Systems, Oct 2022
Performance Modeling of Computer Vision-based CNN on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, Smail Niar, and Abdessamad Ait El CadiACM Transactions on Embedded Computing Systems, Oct 2022Convolutional Neural Networks (CNNs) are currently widely used in various fields, particularly for computer vision applications. Edge platforms have drawn tremendous attention from academia and industry due to their ability to improve execution time and preserve privacy. However, edge platforms struggle to satisfy CNNs’ needs due to their computation and energy constraints. Thus, it is challenging to find the most efficient CNN that respects accuracy, time, energy, and memory footprint constraints for a target edge platform. Furthermore, given the size of the design space of CNNs and hardware platforms, performance evaluation of CNNs entails several efforts. Consequently, designers need tools to quickly explore large design space and select the CNN that offers the best performance trade-off for a set of hardware platforms. This article proposes a Machine Learning (ML)–based modeling approach for CNN performances on edge GPU-based platforms for vision applications. We implement and compare five of the most successful ML algorithms for accurate and rapid CNN performance predictions on three different edge GPUs in image classification. Experimental results demonstrate the robustness and usefulness of our proposed methodology. For three of the five ML algorithms — XGBoost, Random Forest, and Ridge Polynomial regression — average errors of 11%, 6%, and 8% have been obtained for CNN inference execution time, power consumption, and memory usage, respectively.
-
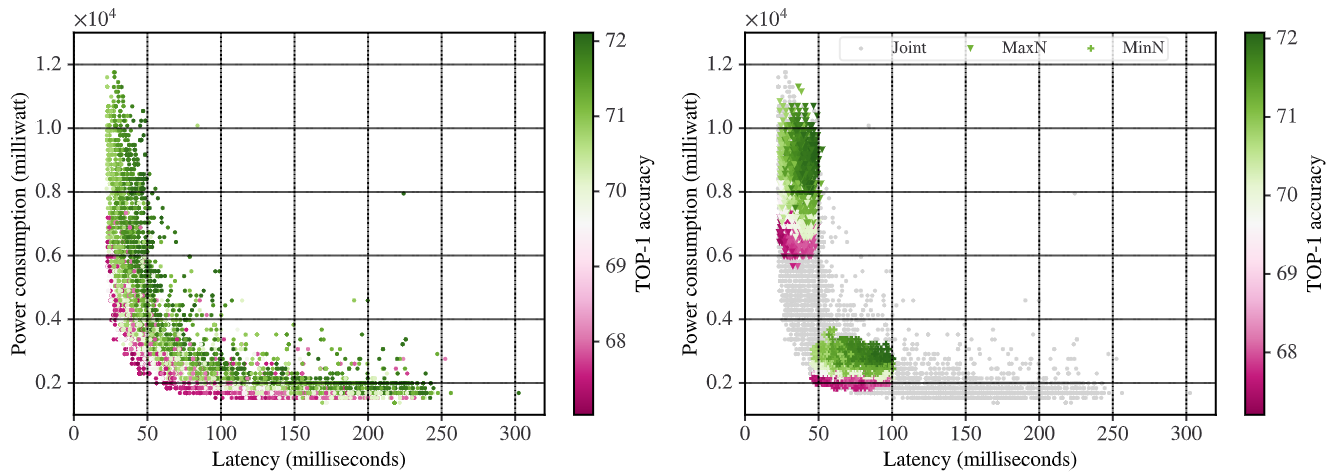 Evolutionary-Based Co-optimization of DNN and Hardware Configurations on Edge GPUHalima Bouzidi, Hamza Ouarnoughi, El-Ghazali Talbi, Abdessamad Ait El Cadi, and Smail NiarIn , Oct 2022
Evolutionary-Based Co-optimization of DNN and Hardware Configurations on Edge GPUHalima Bouzidi, Hamza Ouarnoughi, El-Ghazali Talbi, Abdessamad Ait El Cadi, and Smail NiarIn , Oct 2022The ever-increasing complexity of both Deep Neural Networks (DNN) and hardware accelerators has made the co-optimization of these domains extremely complex. Previous works typically focus on optimizing DNNs given a fixed hardware configuration or optimizing a specific hardware architecture given a fixed DNN model. Recently, the importance of the joint exploration of the two spaces draw more and more attention. Our work targets the co-optimization of DNN and hardware configurations on edge GPU accelerator. We investigate the importance of the joint exploration of DNN and edge GPU configurations. We propose an evolutionary-based co-optimization strategy for DNN by considering three metrics: DNN accuracy, execution latency, and power consumption. By combining the two search spaces, we have observed that we can explore more solutions and obtain a better tradeoff between DNN accuracy and hardware efficiency. Experimental results show that the co-optimization outperforms the optimization of DNN for fixed hardware configuration with up to 53% hardware efficiency gains for the same accuracy and latency.



2021
-
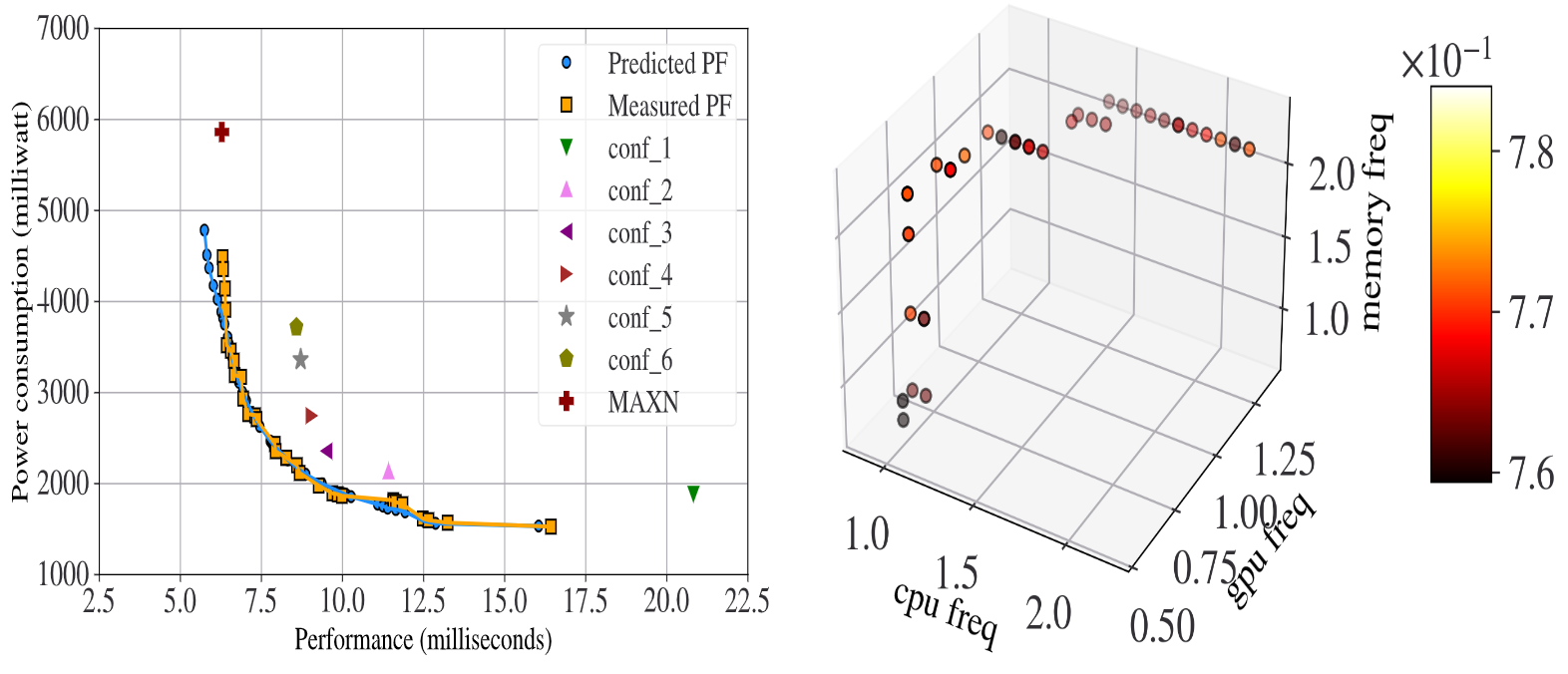 Evolutionary-based Optimization of Hardware Configurations for DNN on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, El-Ghazali Talbi, Abdessamad Ait El Cadi, and Smail NiarIn META’21, The 8th International Conference on Metaheuristics and Nature Inspired Computing, Oct 2021
Evolutionary-based Optimization of Hardware Configurations for DNN on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, El-Ghazali Talbi, Abdessamad Ait El Cadi, and Smail NiarIn META’21, The 8th International Conference on Metaheuristics and Nature Inspired Computing, Oct 2021Performance and power consumption are major concerns for Deep Learning (DL) deployment on Edge hardware platforms. On the one hand, software-level optimization techniques such as pruning and quantization provide promising solutions to minimize power consumption while maintaining reasonable performance for Deep Neural Network (DNN). On the other hand, hardware-level optimization is an important solution to balance performance and power efficiency without changing the DNN application. In this context, many Edge hardware vendors offer the possibility to manually configure the Hardware parameters for a given application. However, this could be a complicated and a tedious task given the large size of the search space and the complexity of the evaluation process. This paper proposes a surrogate-assisted evolutionary algorithm to optimize the hardware parameters for DNNs on heterogeneous Edge GPU platforms. Our method combines both metaheuristics and Machine Learning (ML) to estimate the Pareto-front set of Hardware configurations that achieve the best trade-off between performance and power consumption. We demonstrate that our solution improves upon the default hardware configurations by 21% and 24% with respect to performance and power consumption, respectively.
-
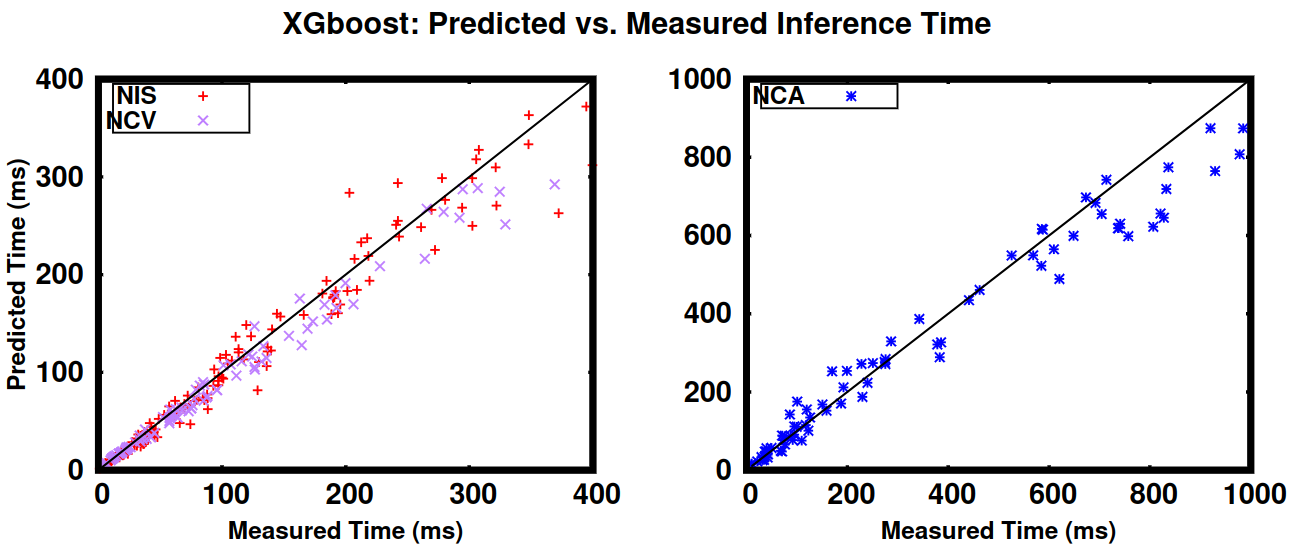 Performance Prediction for Convolutional Neural Networks on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, Smail Niar, and Abdessamad Ait El CadiIn , Virtual Event, Italy, Oct 2021
Performance Prediction for Convolutional Neural Networks on Edge GPUsHalima Bouzidi, Hamza Ouarnoughi, Smail Niar, and Abdessamad Ait El CadiIn , Virtual Event, Italy, Oct 2021Edge computing is increasingly used for Artificial Intelligence (AI) purposes to meet latency, privacy, and energy challenges. Convolutional Neural networks (CNN) are more frequently deployed on Edge devices for several applications. However, due to their constrained computing resources and energy budget, Edge devices struggle to meet CNN’s latency requirements while maintaining good accuracy. It is, therefore, crucial to choose the CNN with the best accuracy and latency trade-off while respecting hardware constraints. This paper presents and compares five of the widely used Machine Learning (ML) based approaches to predict CNN’s inference execution time on Edge GPUs. For these 5 methods, in addition to their prediction accuracy, we also explore the time needed for their training and their hyperparameters’ tuning. Finally, we compare times to run the prediction models on different platforms. The use of these methods will highly facilitate design space exploration by quickly providing the best CNN on a target Edge GPU. Experimental results show that XGBoost provides an interesting average prediction error even for unexplored and unseen CNN architectures. Random Forest depicts comparable accuracy but needs more effort and time to be trained. The other 3 approaches (OLS, MLP, and SVR) are less accurate for CNN performance estimation.

